

대규모 언어 모델(Large Language Model, LLM)을 파인튜닝하기 위해서는 파트 1에서 소개해드렸던 데이터 병렬 처리(Data Parallelism)가 아닌 모델 병렬 처리(Model Parallelism)을 사용하게 됩니다. 대규모 언어 모델과 같이 모델 사이즈가 큰 경우에는 모델 병렬 처리를 활용하여 모델을 분할하고 여러 GPU에 나누어 처리하는 방법을 선택할 수 있습니다.

1. Model Parallelism
1) Naive Model Parallelism(Vertical)
Naive Model Parallelism은 모델의 계층을 여러 GPU에 분할하는 방식입니다. 원하는 계층을 원하는 장치로 전환하고, 데이터가 들어가고 나갈 때마다 해당 계층은 데이터를 계층과 동일한 장치로 전환하고 나머지는 수정되지 않은 상태로 둡니다. 모델의 각 layer들을 수직(vertical)으로 분할하기 때문에 'Vertical Model Parallelism'이라고도 부릅니다.
=================== =================== | 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 | =================== =================== gpu0 gpu1
8개의 layer를 가진 모델에서, Layer 0부터 3까지를 GPU0에 할당하고, 4부터 7까지를 GPU1번에 할당됩니다. 데이터는 Layer0부터 3까지 순차적으로 이동하지만, Layer3에서 4로 전환될 때 GPU 간의 데이터 전송이 필요합니다. 만약 두 GPU가 같은 컴퓨터에 있다면, 이 전송은 빠르게 이루어지겠지만, 서로 다른 컴퓨터에 위치한다면 통신 오버헤드가 클 수 있습니다.
Naive Model Parallelism의 가장 큰 문제점은 한 번에 하나의 GPU만 활성화되어 있다는 것입니다. 나머지 GPU들은 대기 상태에 머무르게 됩니다. 또한, GPU 간의 데이터 전송 오버헤드도 존재합니다. 예를 들어, 4x6GB 크기의 GPU가 있다면, 이론적으로는 1x24GB의 GPU와 동일한 작업을 수행할 수 있겠지만, 실제로는 이 오버헤드 때문에 처리 시간이 더 길어지게 됩니다.
2) Pipeline Parallelism(PP)
Pipeline Parallelism(PP)는 Naive Model Pallelism과 거의 동일하지만, 들어오는 Batch를 micro-batch로 chunck(청크)하고, 여러 GPU가 계산 프로세스에 동시에 작업을 참여할 수 있게 하는 파이프라인을 만들어, GPU 유휴 문제를 해결합니다.
GPipe paper에 나오는 아래 그림은 Naive Model Parallelism과 Pipeline Parallelism를 설명합니다.
상단의 그림은 Naive MP로, 네트워크의 순차적 특성으로 인해 GPU사용의 심각한 저활용률을 보여주고 있습니다. 반면 하단의 그림은 Pipeline Parallelism으로, Input Mini Batch를 더 작은 Micro-Batch들로 분할하여, GPU들이 동시에 개별 Micro-Batch에서 작업할 수 있게 합니다. GPU가 작업을 하지 않는 유휴 상태인 Deadzone을 Bubble이라고 하는데, Naive MP보다 PP가 Bubble의 크기가 더 작은 것을 확인할 수 있습니다.
그림은 4개의 GPU를 사용하는 병렬 처리를 보여주며, 각 GPU는 F0, F1, F2, F3의 Forward Pass와 B3, B2, B1, B0 순으로 진행되는 Backward Pass를 진행합니다. 다만 PP는 새로운 하이퍼파라미터인 '청크(chunks)'가 존재합니다. 청크는 동일한 파이프 스테이지를 통해 연속으로 전송되는 데이터 조각의 수를 정의합니다. 그림은 청크 파라미터가 4일 때를 보여주는데, GPU0은 청크 0, 1, 2, 3에 대해 동일한 Forward Pass를 수행합니다(F(0,0), F(0,1), F(0,2), F(0,3)), 그런 다음 다른 GPU들이 작업을 수행할 때까지 기다린 후, 그들의 작업이 완료되기 시작할 때, GPU0는 다시 작업을 시작하며 청크 3, 2, 1, 0에 대해 Backward Pass를 수행합니다(B0,3, B0,2, B0,1, B0,0).
이는 'Gradient Accumulation Steps(GAS)'와 개념적으로 동일합니다. 한정적인 GPU 메모리 상태에서 배치 크기를 늘리고 싶을 때 사용하는 GAS는 미니 배치를 통해 구해진 gradient를 n-step 동안 Global Gradients에 누적시킨 후, 한 번에 업데이트를 하는 방식으로 더 큰 배치 사이즈와 같은 효과를 냅니다.
청크 파라미터로 PP는 마이크로 배치(Micro-Batches, MBS)의 개념을 도입합니다. 데이터 병렬 처리(Data Parallel, DP)는 글로벌 데이터 배치 크기를 미니 배치로 분할합니다. 따라서 DP 단계가 4라면, 글로벌 배치 크기가 1024인 경우, 이는 각각 256 크기의 4개의 미니 배치로 분할됩니다(1024/4). 청크의 수가 32인 경우, 마이크로 배치 크기는 8(256/32)이 됩니다. 각 파이프라인 단계는 한 번에 하나의 마이크로 배치로 작업합니다. 따라서 Data Parallel과 Pipeline Parallelism을 동시에 사용할 때의 Global Batch Size는 아래와 같이 계산합니다.
MBS * Chunks * dp_degree = 8 * 32 * 4 = 1024
이때, 청크의 값을 조절하는 것도 매우 중요한데, 청크가 1일 경우 Naive Model Parallelism과 다를 바가 없고, 청크의 값이 매우 클 경우, 마이크로 배치 사이즈가 너무 작아져 효율적이 떨어질 수 있습니다. 따라서 GPU의 효율적인 활용을 최대화하는 청크 값이 얼마인지 실험을 통해 찾아야 합니다.
DeepSpeed, Varuna, SageMaker는 Interleaved Pipeline의 개념을 도입해, Backward Pass의 우선순위를 지정하여 Bubble를 추가로 최소화합니다. Varuna는 시뮬레이션을 사용하여 가장 효율적인 스케쥴링을 발견함으로써 일정을 개선하려고 합니다.
3) Tensor Parallelism
Tensor Parallelsim에서는 각 GPU는 Tensor의 Slice를 처리하고, 전체를 필요로 하는 연산에 대해 전체 텐서를 집계합니다. Tensor Parallelism은 Megatron-LM 논문의 컨셉과 이미지를 사용하여 설명합니다.
모든 Transformer의 주요 구성 블록은 fully connected nn.Linear에 이어 nonlinear activation GeLU입니다. Megatron-LM 논문에서는 dot-product 파트를 Y=GeLU(XA)로 표현하는데, X와 Y는 각각 input, output vector이고, A는 weight matrix입니다. 행렬 형태의 계산을 보면 행렬 곱셈이 여러 GPU 간에 어떻게 분할될 수 있는지 쉽게 알 수 있습니다.
가중치 행렬 A를 N개의 GPU에 걸쳐 열 단위로 분할하고, 행렬 곱셈 XA_1~XA_n을 병렬로 수행하면, 독립적으로 GeLU에 입력할 수 있는 N개의 출력 벡터 Y_1~Y_n이 됩니다.

이 원리로 마지막까지 GPU 간의 동기화 없이 Multi-layer Perceptron(MLP)를 업데이트 할 수 있고, shard에서 출력 벡터를 재구성해야 합니다.
Multi-headed attention layer를 병렬화하는 것은 여러 개의 독립적인 헤드가 있는, 이미 병렬화되어 있기 때문에 훨씬 더 간단합니다.
TP는 매우 빠른 네트워크를 요구합니다. 따라서 TP를 하나 이상의 node에서 사용하지 않는 것이 좋습니다.
2. Fully Shared Data Parallel
모델이 너무 커서 단일 GPU에 수용할 수 없다면, 모델 샤딩이라는 다른 기법을 살펴봐야합니다. 모델 샤딩의 인기 있는 구현은 pytorch의 Fully Sharded Data Parallel 입니다. FSDP는 2019년에 Microsoft의 연구자들이 제안한 ZeRO라는 기법에 기반을 두었습니다.
FSDP를 사용하면, 데이터를 Distributed Data Parallel(DDP)와 같이 여러 GPU에 분배하지만, 모델 파라미터, 그래디언트, 옵티마이저 상태도 GPU 노드 간에 샤딩합니다. 이전에 논의한 DDP와 달리, FSDP는 각 배치의 데이터를 처리하기 위해 필요한 모든 모델 상태를 각 GPU가 로컬에 갖지 않으므로, 순전파 및 역전파를 수행하기 전에 이 데이터를 모든 GPU에서 수집해야 합니다.
마지막으로, FSDP는 학습 계산의 일부를 CPU로 오프로드함으로써 GPU 메모리 사용량을 더욱 줄일 수 있습니다. 이는 성능과 메모리 사용량 사이의 상충 관계를 관리하는 데 사용할 수 있습니다.
모델 크기가 증가하고 더 많은 GPU에 분산됨에 따라, 칩 간의 통신량 증가가 성능에 영향을 미쳐 계산 속도를 늦추게 됩니다. 요약하자면, FSDP는 작은 모델과 큰 모델 모두에 사용할 수 있으며, 여러 GPU에 모델 학습을 무리 없이 확장할 수 있습니다.
모델을 여러 GPU에서 학습시키는 것은 비용이 많이 들고 기술적으로 복잡하기 때문에, 일부 연구자들은 더 작은 모델로 더 나은 성능을 달성하는 방법을 연구하고 있습니다.
3. ZeRO Data Parallelism
ZeRO는 Zero Redundancy Optimizer의 약자로, GPU 간에 중복 데이터 없이 모델 상태를 분배하거나 샤딩함으로써 메모리를 최적화하는 것이 목표입니다. ZeRO는 세 가지 최적화 단계를 제공합니다. ZeRO 단계 1은 옵티마이저 상태만 GPU 간에 샤딩하며, 이는 메모리 사용량을 최대 4배까지 줄일 수 있습니다. ZeRO 단계 2는 그래디언트도 칩 간에 샤딩하며, 단계 1과 함께 적용하면 메모리 사용량을 최대 8배까지 줄일 수 있습니다. 마지막으로, ZeRO 단계 3는 모델 파라미터를 포함한 모든 구성 요소를 GPU 간에 샤딩합니다. 단계 1과 2와 함께 적용하면 메모리 축소는 GPU의 수에 비례합니다.

DataParallel(DP)와 유사하지만, 모델의 전체 파라미터, 그래디언트, 옵티마이저 상태를 복제(replicate)하는 대신 각 GPU는 그 슬라이스만 저장합니다. 그리고 given layer에 full layer params가 필요한 런타임에 모든 GPU가 동기화되어 서로 놓친 부분을 제공합니다.
예를 들어, 3 layer를 가진 간단한 모델이라고 가정할 때, 각 layer들은 3개의 파라미터를 가집니다. Layer a, La는 a0, a1, a2라는 weights를 가집니다.
La | Lb | Lc ---|----|--- a0 | b0 | c0 a1 | b1 | c1 a2 | b2 | c2
만약 3개의 GPU가 있다면, Sharded DDP(=Zero-DP)는 3개의 GPU에 모델을 쪼개어 나누어 줍니다.
GPU0: La | Lb | Lc ---|----|--- a0 | b0 | c0 GPU1: La | Lb | Lc ---|----|--- a1 | b1 | c1 GPU2: La | Lb | Lc ---|----|--- a2 | b2 | c2
각각의 GPU들은 DP처럼 mini-batch를 갖게 됩니다.
x0 => GPU0 x1 => GPU1 x2 => GPU2
먼저 입력이 layer La에 도달합니다. GPU 0번은 x0에서 forward path 하기 위해 모든 a0, a1, a2 파라미터들이 필요합니다. 하지만 GPU 0번은 오직 a0을 갖고 있기 때문에 GPU 1번에서 a1을, GPU 2번에서 a2를 보내어 모델의 모든 부분을 하나로 묶습니다.
이와 병행하여, GPU 1번은 a1은 있지만, a0과 a2 파라미터가 없기 때문에, GPU 0번과 GPU 2번에서 이를 얻습니다. 동일한 일이 역시 GPU 2번에서도 벌어집니다. 3개의 GPU가 모두 전체 텐서를 재구성하면, forward path가 발생합니다. 이때 계산이 완료되는 즉시 더 이상 필요하지 않은 데이터가 삭제됩니다. 같은 프로세스가 Layer Lb와 Layer Lc에도 적용이 되고, forward-wise 하게 프로세스가 진행된 후에는 Lc→Lb→La 순으로 backward 하게 진행됩니다.
4. 2D or 3D Parallelism
다양한 Parallelism 방법들을 함께 사용하는 것을 2D or 3D Parallelism이라고 하며, 이는 더 큰 모델 혹은 좀 더 빠르게 모델을 훈련할 수 있게 만듭니다.
1) DP + PP

위 그림은 Deepspeed pipeline tutorial에서 소개한 DP를 PP와 함께 사용하는 방법입니다. DP rank0이 GPU2를 보지 않고 DP rank1이 GPU3을 보지 않는 방법을 보는 것이 중요합니다. DP에는 GPU가 2개뿐인 것처럼 데이터를 공급하는 GPU0과 1만 있습니다. GPU0은 PP를 사용하여 GPU2에게 은밀하게 로드의 일부를 오프로드 합니다. GPU1은 GPU3을 지원에 등록함으써 동일한 작업을 수행합니다. 각 차원에는 최소 2개의 GPU가 필요하므로 여기서는 최소 4개의 GPU가 필요합니다.
2) DP + PP + TP
보다 효율적인 훈련을 위해 PP가 TP 및 DP와 결합된 3D 병렬 방식이 사용됩니다. 이는 다음 다이어그램에서 확인할 수 있습니다.
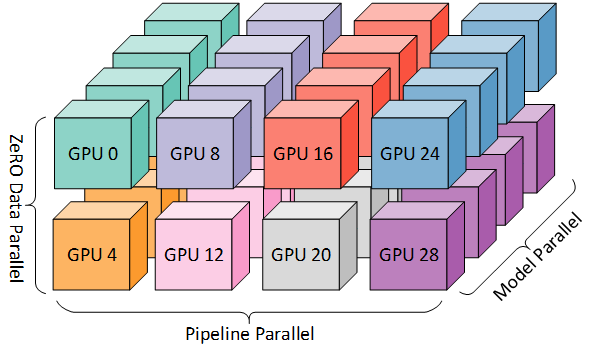
각 차원에는 최소 2개의 GPU가 필요하므로 여기서는 최소 8개의 GPU가 필요합니다.
3) DP + PP + TP + ZeRO
딥스피드의 주요 기능 중 하나는 DP의 초 확장 기능인 Zero입니다. 일반적으로 PP나 TP가 필요 없는 독립형 기능이지만 PP와 TP를 결합할 수 있습니다. ZeRO-DP가 PP(선택적으로 TP)와 결합되면 일반적으로 ZeRO 단계 1(옵티마이저 샤딩)만 활성화합니다. 이론적으로 파이프라인 병렬과 함께 Zero 단계 2(그레이디언트 샤딩)를 사용하는 것이 가능하지만 성능에 나쁜 영향을 미칠 것입니다. 샤딩 전에 그래디언트를 집계하기 위해 모든 마이크로 배치에 대한 추가적인 reduce-scatter collective이 필요하며, 이는 잠재적으로 상당한 통신 오버헤드를 추가합니다.
5. 상황별 Parallelism 선택
1) 단일 GPU
- 단일 GPU에 모델이 맞을 때:
- 일반 사용
- 단일 GPU에 모델이 맞지 않을 때:
- ZeRO + CPU Offload or NVMe
- 가장 큰 계층(Layer)이 단일 GPU에 맞지 않으면 Memory Centric Tiling 추가 사용
- 가장 큰 계층(Layer)이 단일 GPU에 맞지 않을 때:
- ZeRO의 Memory Centric Tiling(MCT) 활성화: 임의의 큰 계층을 자동으로 분할하고 순차적으로 실행
2) Single Node / Multi-GPU
- 모델이 단일 GPU에 맞을 때:
- DDP(분산 데이터 병렬 처리)
- ZeRO
- 모델이 단일 GPU에 맞지 않을 때: NVLINK 또는 NVSwitch와 같이 매우 빠른 GPU 간 연결성이 있다면 이 세 방법은 대체로 유사한 성능을 보이지만, 연결성이 없다면 PP가 TP 혹은 ZeRO보다 빠를 수 있습니다.
- PP
- TP
- ZeRO
- 가장 큰 계층이 단일 GPU에 맞지 않을 때:
- TP
- ZeRO
3) Multi Node / Multi-GPU
- 빠른 inter-node 연결성이 있을 때:
- ZeRO: 모델에 거의 수정 없이 가능하다.
- PP + TP + DP: 통신이 적지만 모델에 큰 변화가 필요하다.
- 느린 inter-node 연결성이 있을 때:
- DP + PP + TP + ZeRO-1
참조:
https://huggingface.co/docs/transformers/v4.15.0/parallelism
https://pytorch.org/tutorials/beginner/dist_overview.html
'NLP' 카테고리의 다른 글
| Evaluating and Debugging Generative AI: W&B에서 LLM 모니터링 쉽게 하기! (51) | 2023.08.03 |
|---|---|
| 대규모 언어 모델(LLM)과 Prompt Engineering 이해하기 (8) | 2023.07.31 |
| Pytorch Distributed Training을 위한 도구: Accelerate (29) | 2023.07.27 |
| LLM 파인튜닝을 위한 GPU 분산 학습 정복하기 PART 1 (2) | 2023.07.27 |
| PEFT를 활용한 PLM 파인튜닝 가이드 (0) | 2023.07.21 |