

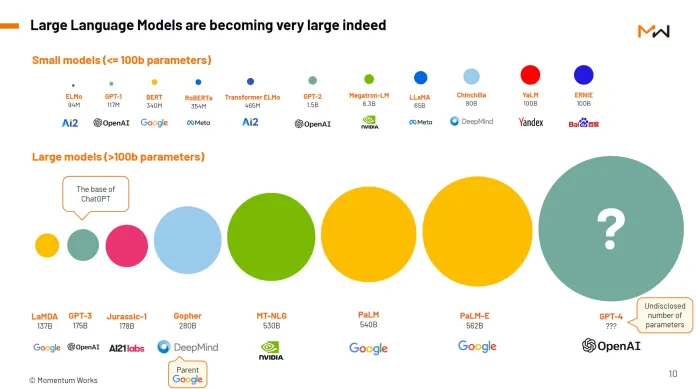
1. Generative AI란?
Generative AI는 텍스트나 이미지를 생성하는 능력을 가진 AI로, 다양한 분야에서 활용되고 있습니다. 대표적인 예로는 텍스트 생성에 특화된 OpenAI사의 ChatGPT와 이미지를 생성하는 Midjourney가 있습니다.

저는 개인적으로 개발 과정에서는 Copilot이라는 도구를 유용하게 활용하고 있습니다. 이는 코딩을 도와주는 Visual Studio Code의 플러그인으로, 간단하게 설치하고 사용할 수 있습니다.

이런 Generative AI 도구들은 기본적으로 인간의 능력에 근접하거나, 그를 모방하는 것을 목표로 합니다. 대규모 언어 모델 (Large Language Model, LLM)은 인간이 생성한 대량의 데이터를 학습하여, 인간의 행동을 따라 하려고 노력합니다. 이 과정에는 수조 단어에 이르는 거대한 데이터셋, 오랜 시간의 훈련, 그리고 강력한 컴퓨팅 파워가 필요합니다.
이렇게 학습된 모델들을 "Foundation model"이라 부르며, 이들은 수십억 개의 파라미터를 통해 언어 이상의 특성을 표현할 수 있습니다. 이런 기능을 활용하여, 우리는 복잡한 문제를 해결하고, 추론하는 능력을 갖춘 AI를 개발하려고 합니다.
2. Large Language Model(LLM)과 Prompt Engineering
LLM은 기존의 머신러닝 모델과는 달리, 인간의 언어를 이해하고, 사용자로부터 제공받은 지시사항에 따라 인간과 유사하게 작업을 수행하는 능력을 갖추고 있습니다. 이는 기계학습 알고리즘을 통해 구현되며, 텍스트 형태의 입력을 통해 사용자의 의도를 파악하고 적절한 반응을 생성합니다.
이러한 언어 모델에 텍스트를 제공하는 것을 '프롬프트(Prompt)'라고 합니다. 프롬프트는 사용자의 지시사항, 질문, 요청 등이 될 수 있으며, 모델이 이를 해석하고 처리해 원하는 출력을 얻게 됩니다. ChatGPT와 소통하기 위한 텍스트창이나, Midjourney로 그림을 생성하기 위한 텍스트창이 프롬프트라고 불립니다.
또한 언어 모델이 텍스트를 처리하고 정보를 저장하는 공간을 'Context Window'라고 부릅니다. 일반적으로 몇 천 단어의 정보를 처리하고 저장할 수 있는 이 Context Window는 모델이 사용자의 입력을 이해하고, 과거의 정보를 현재의 상황에 적용하는데 큰 역할을 합니다.
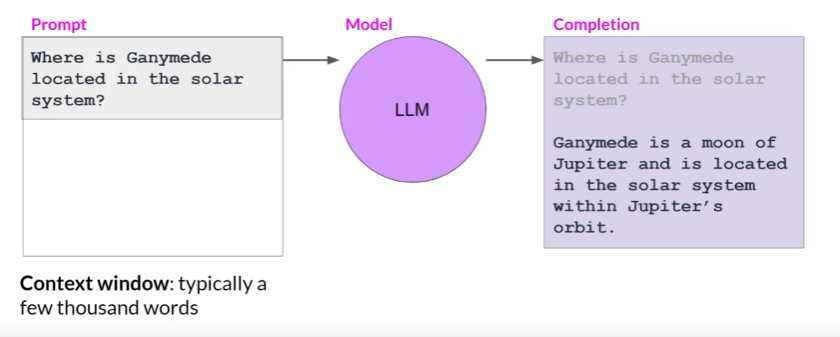
예를 들어, LLM에게 "Where is Ganymede located in the solar system?(Ganymede가 태양계 어디에 위치하는가?)"라는 질문을 던졌다고 생각해 봅니다. 이 문장은 모델에게 전달되는 '프롬프트'가 됩니다. 이 프롬프트가 모델에게 전달되면, 모델은 다음 단어나 문장을 예측하고, 프롬프트가 질문을 포함하고 있기 때문에 해당 모델은 답변을 생성합니다. 이렇게 모델이 생성하는 텍스트 출력을 'Completion'이라고 부릅니다. 그리고 이런 방식으로 모델이 텍스트를 생성하는 전체 과정은 'Inference'라고 합니다.
그러나 모든 프롬프트가 동일하게 좋은 결과를 가져다주는 것은 아닙니다. 더 나은 품질을 답변을 얻기 위해 프롬프트를 정교하게 조정하거나 최적화하는 작업을 수행하기도 하는데, 이를 'Prompt Engineering'이라고 합니다. 모델이 더 좋은 결과를 출력하도록 하는 강력한 전략 중 하나는 모델이 수행해야 할 작업의 예시를 프롬프트 안에 포함하는 것입니다. 프롬프트 내에서 입력 데이터를 제공하는 것을 'In-Context Learning(ICL)'이라고 합니다. In-Context Learning을 통해 프롬프트에 예시나 추가 데이터를 포함시켜 작업에 대해 더 많이 학습하도록 도울 수 있습니다.
1) Zero-shot Inference
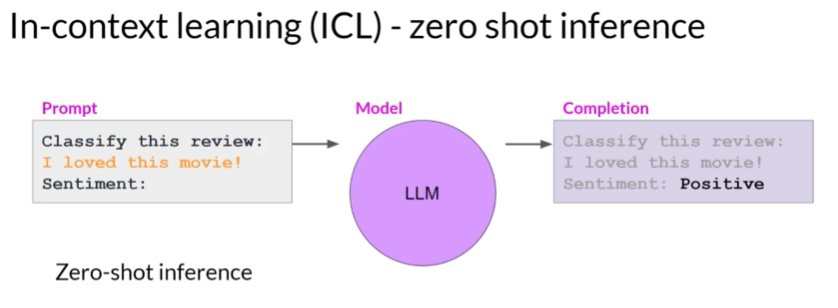
In-Context Learning을 이해하기 위해 예시를 살펴보겠습니다. LLM에게 리뷰의 감성(영화 리뷰가 긍정적인지 부정적인지)를 분류하도록 요청합니다. 프롬프트는 "Classify this review:"라는 지시, "I loved this movie!"라는 리뷰 텍스트, 그리고 "Sentiment:"라는 옆에 감성 분류의 결과를 출력하도록 하는 지시로 이루어져 있습니다. 이러한 방식으로 입력 데이터를 직접 프롬프트 내에 포함시키는 방법을 'Zero-shot inference'라고 합니다. 일반적으로 대규모 언어 모델들은 이러한 방식의 작업을 잘 수행하며, 제공된 문맥과 작업을 잘 이해하고 적절한 답변을 제공합니다. 이 예시에서 모델은 감성을 "Positive"로 올바르게 판별했습니다.
2) One-shot Inference
하지만 모든 모델이 이런 작업을 잘 수행하는 것은 아닙니다. 예를 들어 GPT-2와 같은 상대적으로 작은 모델들은 이런 종류의 작업에서 어려움을 겪을 수 있습니다. 작업과 관련된 텍스트를 어느 정도 생성하기는 하지만, 작업의 세부 사항을 완전히 이해하지 못하고 감성을 정확하게 식별하지 못하는 경우가 있습니다.

이럴 때는 프롬프트에 작업을 보여주는 완료된 예시를 포함시켜 요청합니다. 이전 내용과 동일하게 리뷰 분류 지시 후, 프롬프트 텍스트에는 샘플 리뷰와 해당 리뷰의 감성 분석 결과까지 포함됩니다. 그 아래에 다시 리뷰 분류를 지시 후, 실제 분석할 리뷰를 작성합니다. 이렇게 수정된 프롬프트를 작은 모델에게 제공하면, 모델이 작업과 원하는 응답 형식을 더 잘 이해할 가능성이 높아집니다. 이렇게 하나의 완료된 예시를 포함하는 것을 'One-shot inference'라고 합니다.
3) Few-shot Inference

그러나, 단일 예시만으로는 모델이 원하는 작업을 충분히 학습하는데 부족할 수 있습니다. 이런 경우에는 여러 개의 예시를 포함하여 이 개념을 확장시키는 방법이 있습니다. 이를 'Few-shot Inference'이라고 합니다. 다만, Context Window를 넘어가게 예시를 제시했는데도 모델이 잘 동작하지 않는다면, 데이터를 사용해 모델을 파인튜닝(Fine-tuning)하는 것이 효과적일 수 있습니다.
3. LLM Configuration Parameters
위의 예시들은 언어 모델의 추론 방식과 그들이 어떻게 학습하고 이해하는지를 보여주며, 동시에 프롬프트 엔지니어링의 중요성을 강조하고 있습니다. 이를 통해 언어 모델은 더욱 풍부하고 정교한 응답을 생성할 수 있게 됩니다. 프롬프트를 조정하는 방식 외에도, LLM의 Inference 시 모델 출력에 영향을 미치는 Configuration Parameters가 존재합니다. 이 매개변수들은 모델 학습 때 사용되는 매개변수와는 달리, Inference 시점에 호출되어 모델의 출력의 최대 토큰 수, 출력의 창의성 등을 제어하는 데 사용됩니다.
1) Max new tokens

'Max new tokens'는 모델이 생성할 토큰의 수를 제한하는데 사용됩니다. 'max new tokens'가 설정될 때마다 모델의 출력 길이가 달라집니다. 하지만 max_new_tokens가 200일 경우, 모델이 Stop token을 예측해 200보다 짧게 출력되었습니다. 'Max new tokens'는 모델의 출력의 절대적인 숫자가 아닙니다.
2) Top-k vs Top-p sampling

Transformer의 Softmax 계층에서 출력 되는 것은 모델이 사용하는 전체 단어 사전에 대한 확률 분포입니다. 대부분의 대형 언어 모델은 기본적으로 'Greedy Decoding'을 사용합니다. 이는 단어 예측의 가장 간단한 형태로, 모델은 항상 가장 높은 확률을 가진 단어를 선택합니다. 이 방법은 짧은 생성에 매우 잘 작동하지만, 단어나 단어 시퀀스가 반복되는 것에 취약합니다.
더 자연스럽고 창의적인 텍스트를 생성하고 단어의 반복을 피하려면, 'Random Sampling'을 사용할 수 있습니다. 'Random Sampling'을 사용하면, 모델은 확률 분포를 사용해 가중치를 부여하는 출력 단어를 무작위로 선택합니다. 예를 들어, 'banana'라는 단어가 0.02의 확률 점수를 가진다면, 이 단어가 선택될 확률은 2%입니다. 이 기술을 사용하면, 단어가 반복될 가능성이 줄어듭니다. 하지만 설정에 따라 출력이 너무 창의적일 수 있어 주제나 의미 없는 단어로 이어질 수 있습니다.
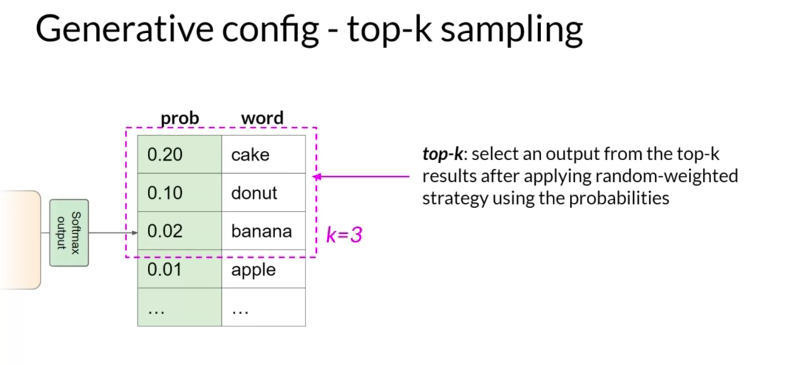

비슷한 맥락에서, top-k와 top-p sampling을 사용하면 Random sampling을 제한하고 출력이 합리적일 확률을 높일 수 있습니다. 더욱 변동성을 주면서도 매우 비합리적인 완성 단어의 선택을 방지하기 위해, k가 가장 높은 확률을 가진 토큰만 선택하도록 모델에 지시하는 top-k 값을 지정할 수 있습니다. 예를 들어, k를 3으로 설정하면, 모델은 이 세 가지 옵션 중에서 선택합니다. 이런 방식으로 모델은 확률 가중치를 사용해 이 옵션 중에서 단어를 선택하며, 이 경우 'donut'를 다음 단어로 선택합니다.
또는 top-p 설정을 사용해 예측의 합계 확률이 p를 초과하지 않는 것들로 Random sampling을 제한할 수 있습니다. 예를 들어, p를 0.3으로 설정하면, 'cake'와 'donut' 옵션을 선택할 수 있으며, 그들의 확률인 0.2와 0.1을 합치면 0.3이 됩니다. 모델은 이 토큰들 중에서 확률 가중치 방식을 사용해 무작위로 선택합니다. top-k에서는 무작위로 선택할 토큰의 수를 지정하고, top-p에서는 모델이 선택할 전체 확률을 지정합니다.
3) Temperature

모델 출력의 무작위성을 제어하는 데 사용할 수 있는 또 다른 매개변수는 'temperature'입니다. temperature는 모델이 다음 토큰에 대해 계산하는 확률 분포의 형태에 영향을 미칩니다. 대체로, temperature가 높을수록 무작위성이 높아지고, 낮을수록 무작위성이 줄어듭니다.
참고:
https://www.coursera.org/learn/generative-ai-with-llms/home/week/1
'NLP' 카테고리의 다른 글
| LLM 파인튜닝을 위한 GPU 분산 학습 정복하기 PART 2 (0) | 2023.08.07 |
|---|---|
| Evaluating and Debugging Generative AI: W&B에서 LLM 모니터링 쉽게 하기! (51) | 2023.08.03 |
| Pytorch Distributed Training을 위한 도구: Accelerate (29) | 2023.07.27 |
| LLM 파인튜닝을 위한 GPU 분산 학습 정복하기 PART 1 (2) | 2023.07.27 |
| PEFT를 활용한 PLM 파인튜닝 가이드 (0) | 2023.07.21 |