

반응형
최근 강화학습 스터디를 시작하면서 블로그를 다시 작성해보려고 한다. 개발 블로그를 열심히 적어보려고 했었지만, 뭔가 나 스스로가 내용 정리가 안되는 느낌이라 포스팅을 하기 쉽지 않았지만, 일단 올려놓고 생각하려고 쓰게 되었다. LLM을 공부하면서 PPO, DPO 같은 강화학습 방법론이 적용되는 것을 보고 강화학습을 처음 알게 되었지만, 논문을 읽어봐도 뭔가 잘 와닿지 않아 스터디를 시작하게 되었다. 참고한 자료는 아래와 같다.
- Huggingface Deep RL Course
- RL Course by David Silver
- 팡요랩 강화학습
처음에는 Huggingface의 Deep RL Course의 수료증 획득을 위해 공부를 시작했지만, 개념이 너무 많이 나오고 구체적인 설명과 예시가 부족해서 이해하기 힘들었다. 그래서 RL을 공부한다면 다들 들어보는 것 같은 David Silver 강의를 들어보기로 했고, 이해가 안되는 부분들은 팡요랩의 강화학습 영상을 함께 보았다. 그래서 앞으로 RL 블로그 포스팅은 강의를 들으면서 정리한 내용을 작성하려고 한다.
1. 목차

2. About Reinforcement Learning
Characteristics of Reinforcement Learning
- 강화학습은 supervisor가 없고 reward signal만 존재
- 답을 알려주는 사람이 없고, agent가 reward signal만 받으면서 좋은 길로 찾아가는 것 ⇒ trial and error paradigm
- reward는 목적하는 바 → agent가 이것을 잘했으면 좋겠다
- 구체적으로 뭘 해야 reward를 많이 받을지 알려주지 않고 agent가 알아서 reward 받는 것을 maximize 하도록 하기
- 알파고도 supervisor 없이, 이기는 것을 maximize 하는 방식으로 사람을 넘어설 수 있었음
- 피드백이 즉각적이지 않음
- 리워드가 무슨 행동을 했을 때, 바로 주어지지 않을 수 있음
- 어떤 행동이 좋은 행동인지 현재 상태에서는 모를 수 있음
- 시간이 중요하다
- RL에서는 sequential process로 진행 ⇒ 스텝별로 agent는 행동을 취하고 보상을 획득
- Supervised Learning에서는 i.i.d(independent and identically distributed) data를 가정 ⇒ 각 샘플이 독립적으로 뽑혀서 서로 영향을 주지 않음
- RL은 다르다 ⇒ dynamic system이고 순서가 매우 중요, 서로 영향을 줄 수 있음
- Agent의 행동이 그 다음의 데이터에 영향을 줌
- agent가 계속 움직이기 때문에 어디 환경에 위치하느냐에 따라 받는 데이터가 계속 달라짐
- 어떤 데이터를 언제 어떻게 받는지도 학습 과정에서 매우 중요함
Examples of Reinforcement Learning
- RL의 예시 중 하나는 헬리콥터가 다양한 스턴트 동작을 하도록 학습시키는 것이 있다 ⇒ 인간이 직접 헬리콥터 모형을 스턴트 동작을 하게 하는 것은 어려운 과제임
- 또한 Agent가 조이스틱으로 Atari 게임을 할 수 있도록 학습 ⇒ 아무것도 알려주지 않은 채 직접 어떤 게임인지 학습시키면 GPU를 사용해서 약 3~4일이면 게임을 잘하도록 할 수 있음
3. The Reinfocement Learning Problem
Rewards
- Reward는 scalar feedback signal Rt
- 각 step t 마다 Agent가 step에 얼마나 잘하고 있는지 알려줌
- Agent의 목표는 cumulative reward를 최대화하는 것
- RL은 reward hypothesis를 기반으로 하고 있는데, 모든 목표는 예상되는 cumulative reward의 최대화로 설명할 수 있다는 것
Sequential Decision Making

- 목표는 미래의 reward를 최대화하기 위해 action을 고르는 것
- 당장의 보상을 포기하고 미래의 보상을 더 얻기 위한 행동도 있음
Agent and Environment
- 뇌는 Agent, 지구는 Environment를 의미
- 각 timestep t에서 agent는 action At를 하고, observation Ot를 환경으로부터 받으며, scalar reward 값 Rt를 받음
- Agent는 오로지 action을 통해서 환경에 영향을 줄 수 있으며, Environment를 볼 수 없고 observation만 볼 수 있음
History and State
- History는 Observations, actions, rewards의 나열
- 무엇이 다음에 일어날 것인지는 History를 기반으로 함
- Agent가 action을 취하고
- Environment는 observation과 reward를 고름
- State는 어떤 것이 벌어질 지 결정하기 위한 정보
- 따라서 state는 history의 function과 같다: St=f(Ht)
Environment State
- Environment state Set는 Environment의 private representation
- 즉 Agent는 environment state를 보통 보지 못하고, 만약 본다고 하더라도 어떤 action을 취하기 위해 Environment state의 모든 정보가 필요로 하지 않음
Agent State
- Agent state Sat는 agent의 internal representation
- Agent는 agent state를 통해서 다음 action을 취하고, RL algorithms에서 사용되는 정보이며, 이전에 말한 function of history(f(Ht))이다
Information State
- Information state(Markov state)는 history의 useful information이 들어있음
- state St는 Markov이라고 불리는데, 다음 state St+1을 결정할 때, 직전 state에만 의존하고, 이전 모든 state들은 참고하지 않아야 함
- 예를 들어, 헬리콥터를 조정하는 task에서, 현재 위치, 가속도, 속도 등을 고려해서 헬리콥터가 추락하지 않게 하려면 핸들을 어떻게 돌릴지 결정할 때, 당장 현재의 상황이 중요하지 10분 전에 헬리콥터의 위치, 가속도, 속도 등이 중요하지 않음
- 결국 현재의 위치, 가속도, 속도에는 이전 상황의 모든 정보가 담겨 있다고 가정하는 것
- 현재 state St는 미래에 대한 충분한 통계치이며, state를 알면 이전 history는 알 필요가 없음
- 따라서 Environment state Set는 Markov이며, history Ht역시 Markov이다
Fully Observable Environments
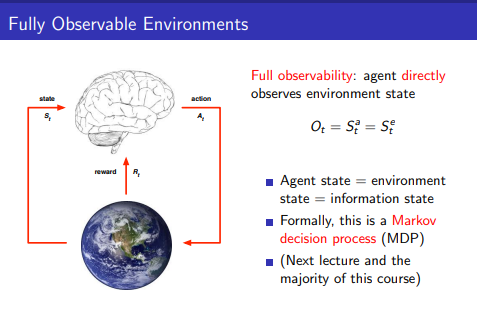
- Fully Observability라는 것은 agent가 직접적으로 environment state를 볼 수 있는 것
Ot=Sat=Set
- 이때는 Agent state와 Environment state와 Information state가 같으며 Markov decision process(MDP)이다.
Partially Observable Environments

- Partially observability는 Agent가 Environment의 일부만 보는 것
- 이때는 Agent state가 Environment state가 아니며 partially observable Markov decision process(POMDP)라고 부름
- Agent는 직접 자신의 state를 구성해야 함
- 이전 history 전체를 state로 볼 수도 있고: Sat=Ht
- 확률 분포를 통해 나타낼 수도 있고
- 확률을 쓰지 않고, 이전 agent state와의 linear conbination을 통해 나타낼 수도 있음
4. Inside An RL Agent
Major Components of an RL Agent

- RL Agent는 Policy, Value function, Model의 요소를 갖고 있거나 없을 수 있음
Policy

- Policy를 따라서 Agent는 Action을 취함
- Deterministic policy이거나 Stochasitic policy일 수 있음
Value Function

- Value function은 미래 보상의 예측
- State의 goodness/badness에 대한 평가를 할 때 사용
- Policy에 대한 value function은 미래 시간에 대한 reward들의 합의 예측
- t+1, t+2 ... 부터 시작해서 γ라는 감쇄계수를 사용해 미래에 대한 Reward를 얼마나 가중치를 둘 것인지 결정
Model

- Model은 환경이 뭘 할지 예측
- Transition Model: P는 그 다음 state를 예측함 (dynamics)
- Reward Model: P는 그 다음 (즉시 받는) reward를 예측함
- 대신 Model은 optional 하며(있을 수도 있고 없을 수 도 있음), 이 강의에서 대부분은 Model free methods를 얘기함
Maze Example

- Reward는 -1 per time-step
- Action은 동서남북으로 이동 가능
- States는 Agent의 현재 위치
- Agent가 Goal에 도착하면 끝나게 됨
Maze Example: Policy
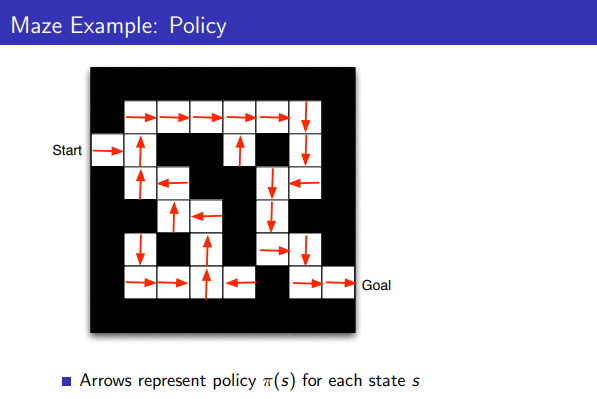
- 화살표는 각 state s에 대해 policy π를 나타냄
Maze Example: Value Function
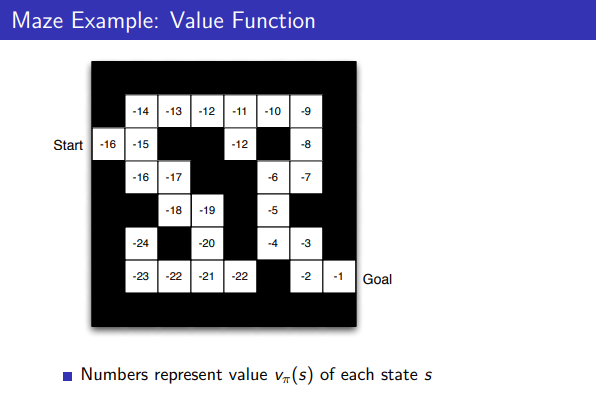
- 숫자들은 각 state s에 대해서 value를 나타냄
Maze Example: Model
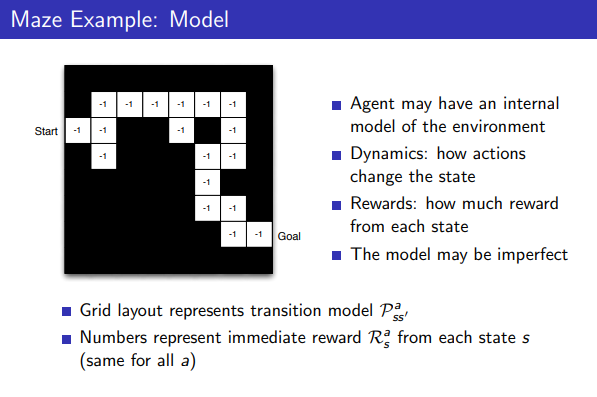
- Agent는 Environment에 대한 internal model이 있을수도 있음
- Model은 완벽하지 않을 수 있음
- 숫자들은 각 state에 대한 즉각적인 보상을 의미함
Categorizing RL agents



- Value based Agent: Value만 보고, Policy가 없음
- Policy based Agent: Policy만 보고, Value가 없음
- Actor Critic Agent: Value와 Policy를 둘다 봄
- Model Free Agent: Poicy 혹은 Value Function이 있고, Model이 없음
- Model Based Agent: Poicy 혹은 Value Function이 있고, Model이 있음
5. Problems within Reinforcement Learning
Learning and Planning

- Reinforcement Learning
- Environment를 모를 때
- Agent가 Environment와 상호작용하고
- Agent가 자신의 policy를 개선한다
- Planning
- Model of the environment를 알 때
- Agent는 다른 외부적인 interaction을 하지 않고, 모델과의 상호작용하며
- Agent가 policy 개선
- 즉 RL은 Environment를 모를 때, Planning은 Environment를 알 때!
Atari Example: Reinforcement Learning
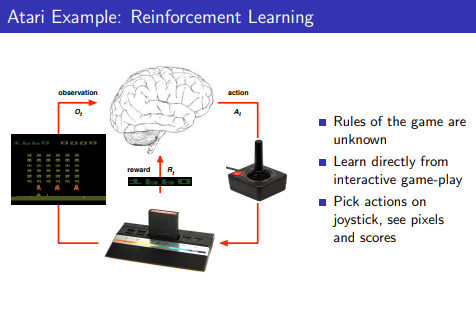
- Atari(게임)에서의 RL
- RL에서는 게임의 규칙은 모른채로 game-play를 통해서 직접적으로 알아감
- Joystick을 통해서 action을 취하고 pixel과 score를 관찰
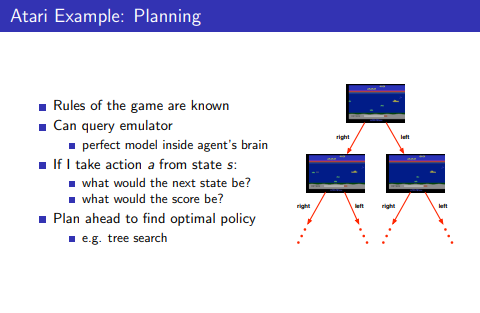
- Atrai에서의 Planning
- 게임의 규칙을 알고, optimal policy를 찾기 위해서 planning 수행
Exploration and Exploitation


- Exploration과 Exploitation
- Exploration: 환경에 대해서 더 많은 정보를 찾아나서는 것
- Exploitation: 주어진 정보를 이용해 reward를 최대화
- Explore하거나 Exploit 하는 것은 둘 다 중요함!
- RL은 시행착오를 겪으면서, 환경에 대한 경험을 토대로 agent는 좋은 policy를 찾아야 함
- 그래서 Explore과 Exploit를 적절히 섞어서 하는 것이 중요함
Examples

- 예를 들어, 레스토랑을 고를 때, 아는 맛의 레스토랑을 가느냐 혹은 더 맛이 있을 수 있는 가능성이 있는 새로운 레스토랑을 탐방해보느냐가 각각 Exploit과 Explore일 수 있음
Prediction and Control

- Prediction: 주어진 policy를 기반으로 future evaluate
- Control: future를 optimise함으로써 optimal policy를 찾아나가는 과정
Gridworld Example: Prediction
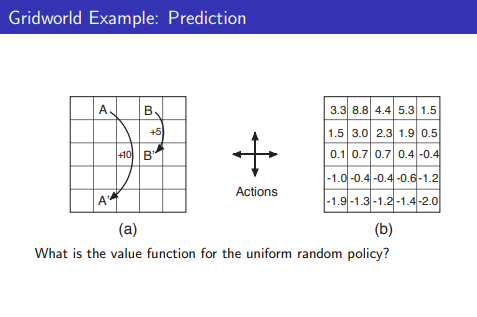
- Random policy를 기반으로 value function을 찾아나감..
Gridworld Example: Control

- Given random policy를 기반으로 Optimal value function을 Prediction을 통해 찾은 후, 그것을 기반으로 optimal policy를 찾아나가는 과정
반응형